Our NewsBots are tools to track the news relevant to a specific task in the investment process, see an application to tracking inflation here. The intuition behind is to catch those events which can have a significant effect on the inflation forecast but don’t show up in usual data, such as regulated price changes, phone plan adjustments, retailers competition, airfares, etc.
This post provides some details about one of our models. We show how Natural Language Processing (NLP) can deal with rather complex tasks when given the right inputs.
Data acquisition and preprocessing
The data come from 50,000 scrapped news wesbsite sources. We query those sources with plain keyword searches.
It would not be optimal to apply the classification model on this dataset straight away. Our sample would be too unbalanced, with the “interesting” news representing fewer than 5% of our sample. To train a model on such data is proved problematic.
So we have added an extra layer of filtering. It is an in-house search engine which looks for a number of inflation related situations. Every article content is analyzed in its integrity. With this method, we are able to reject 80% of the initial news set, getting us a bit closer to a balanced dataset (but the dataset is still unbalanced with roughly only 25% positives).
Labeling
That is certainly the key part. We feed the classification model with examples to distinguish between irrelevant (class 0) and relevant (class 1) news, from the point of view of forecasting inflation.
The task is a bit more complex than most classification problems in the ML literature, such as distinguishing between T-shirts and shoes pictures, or looking for positive and negative reviews to stick with NLP.
There is a gray era in NLP labeling. For this task, the inherent imprecision could be as high as 4 to 5%. This is worth keeping in mind for when we asses our model’s performance. There won’t be such thing as perfect precision that we should expect (unless the model overfits). “Perfect” precision is in reality closer to 95% than 100% in this task unlike, once again, distinguishing between T-shirs and shoes.
Benchmark classification model
The labeling has been done in iterative steps, helping the model reach a conclusion for the most difficult cases.
Our base model is BERT, the neural network language model developed by a Google team which revolutionised language processing a couple of years ago. We have found it easier to fine-tune without as much hyperparameter tweaking as some other models in the same class.
We left aside 10% of the sample for validation and another 10% for testing. Here are the classification model main stats over validation and testing:

The first observation is the limited amount of over-fitting: the model’s performance doesn’t deteriorate in a significant way between the two stages.
Second, this 91% overall accuracy is generally acceptable when we take into account the inherent uncertainty in the task mentionned before. If the target was 95%, we are reasonably close.
Third, the share of label 1 (relevant) items which are caught (recall) is around 85%. Said differently, the model misses around 15% of the relevant news. Given the large unbalance between the two classes, this is a fine result.
Last, we can compare those results with a benchmark model, an IF-IDF vectorizer coupled with an optimised naive Bayes classifier, for instance looking at the AUC:
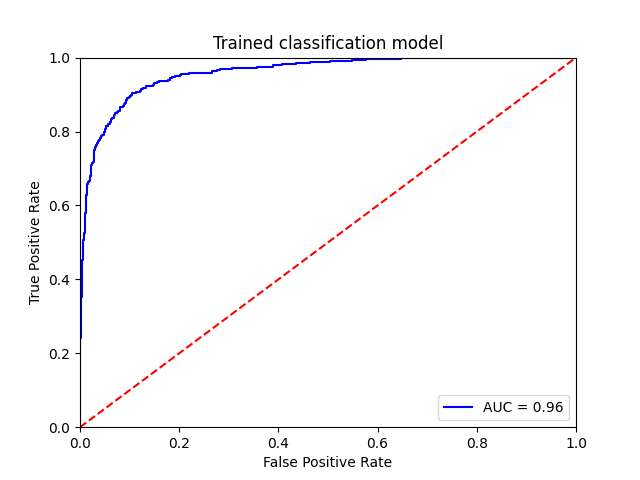
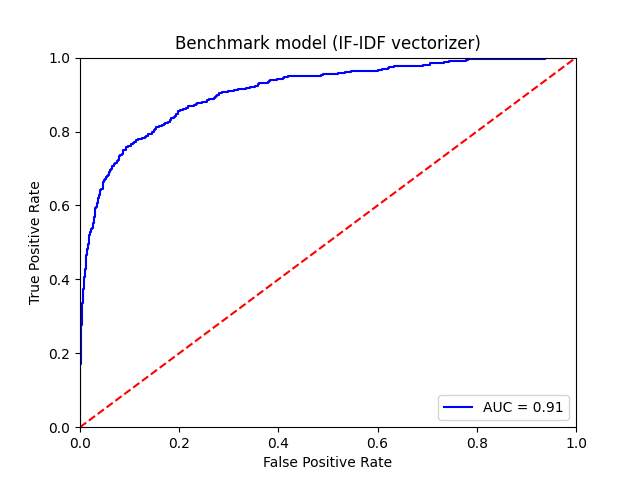
The benchmark model has seen its hyperparameters optimized, for a fair competition. The benchmark model reaches 80% accuracy on the test set, which is 11 percentage points below the fine-tuned BERT model. The AUC is a full 5 points lower, so precision and recall are significnatly worse.
The fine-tuned BERT model is for now as good as things get with this type of task. It will keep marginally improving with new data.
We have assigned a difficult task to the language model, but it can cope. The model is still a bit less accurate than the expert, but it is not ridiculously far behind. The volume more than compensates the slight difference in accuracy with the expert: the algo can process hundreds of thousands of news while we, human, will have time for a few tens, at best.
